L1 <--> L2 communication
In the following section, we will look at cross-chain communication, mixing L1 and L2 for composability and profits.
Objective
The goal is to set up a minimal-complexity mechanism, that will allow a base-layer (L1) and the Aztec Network (L2) to communicate arbitrary messages such that:
- L2 functions can
callL1 functions. - L1 functions can
callL2 functions. - The rollup-block size have a limited impact by the messages and their size.
High Level Overview
This document will contain communication abstractions that we use to support interaction between private functions, public functions and Layer 1 portal contracts.
Fundamental restrictions for Aztec:
- L1 and L2 have very different execution environments, stuff that is cheap on L1 is most often expensive on L2 and vice versa. As an example,
keccak256is cheap on L1, but very expensive on L2. - L1 and L2 have causal ordering, simply meaning that we cannot execute something on L1 that depends on something happening on L2 and vice versa.
- Private function calls are fully "prepared" and proven by the user, which provides the kernel proof along with commitments and nullifiers to the sequencer.
- Public functions altering public state (updatable storage) must be executed at the current "head" of the chain, which only the sequencer can ensure, so these must be executed separately to the private functions.
- Private and public functions within Aztec are therefore ordered such that first private functions are executed, and then public. For a more detailed description of why, see above.
- There is an explicit 1:1 link from a L2 contract to an L1 contract, and only the messages between a pair is allowed. See Portal for more information.
- Messages are consumables, and can only be consumed by the recipient. See Message Boxes for more information.
With the aforementioned restrictions taken into account, cross-chain messages can be operated in a similar manner to when public functions must transmit information to private functions. In such a scenario, a "message" is created and conveyed to the recipient for future use. It is worth noting that any call made between different domains (private, public, cross-chain) is unilateral in nature. In other words, the caller is unaware of the outcome of the initiated call until told when some later rollup is executed (if at all). This can be regarded as message passing, providing us with a consistent mental model across all domains, which is convenient.
As an illustration, suppose a private function adds a cross-chain call. In such a case, the private function would not have knowledge of the result of the cross-chain call within the same rollup (since it has yet to be executed).
Similarly to the ordering of private and public functions, we can also reap the benefits of intentionally ordering messages between L1 and L2. When a message is sent from L1 to L2, it has been "emitted" by an action in the past (an L1 interaction), allowing us to add it to the list of consumables at the "beginning" of the block execution. This practical approach means that a message could be consumed in the same block it is included. In a sophisticated setup, rollup could send an L2 to L1 message that is then consumed on L1, and the response is added already in . However, messages going from L2 to L1 will be added as they are emitted.
Because everything is unilateral and async, the application developer have to explicitly handle failure cases such that user can gracefully recover. Example where recovering is of utmost importance is token bridges, where it is very inconvenient if the locking of funds on one domain occur, but never the minting or unlocking on the other.
Components
Portal
A "portal" refers to the part of an application residing on L1, which is associated with a particular L2 address (the confidential part of the application). The link between them is established explicitly to reduce access control complexity. On public chains, access control information such as a whitelist in a mapping or similar data structure can simply be placed in public storage. However, this is not feasible for contracts in Aztec. Recall that public storage can only be accessed (up to date) by public functions which are called AFTER the private functions. This implies that access control values in public storage only work for public functions. One possible workaround is to store them in private data, but this is not always practical for generic token bridges and other similar use cases where the values must be publicly known to ensure that the system remains operational. Instead, we chose to use a hard link between the portal and the L2 address.
Note, that we at no point require the "portal" to be a contract, it could be an EOA on L1.
Message Boxes
In a logical sense, a Message Box functions as a one-way message passing mechanism with two ends, one residing on each side of the divide, i.e., one component on L1 and another on L2. Essentially, these boxes are utilized to transmit messages between L1 and L2 via the rollup contract. The boxes can be envisaged as multi-sets that enable the same message to be inserted numerous times, a feature that is necessary to accommodate scenarios where, for instance, "deposit 10 eth to A" is required multiple times. The diagram below provides a detailed illustration of how one can perceive a message box in a logical context.

- Here, a
senderwill insert a message into thependingset, the specific constraints of the actions depend on the implementation domain, but for now, say that anyone can insert into the pending set. - At some point, a rollup will be executed, in this step messages are "moved" from pending on Domain A, to ready on Domain B. Note that consuming the message is "pulling & deleting" (or nullifying). The action is atomic, so a message that is consumed from the pending set MUST be added to the ready set, or the state transition should fail. A further constraint on moving messages along the way, is that only messages where the
senderandrecipientpair exists in a leaf in the contracts tree are allowed! - When the message have been added to the ready set, the
recipientcan consume the message as part of a function call.
Something that might seem weird when comparing to other cross-chain setups, is that we are "pulling" messages, and that the message don't need to be calldata for a function call. For Abritrum and the like, execution is happening FROM the "message bridge", which then calls the L1 contract. For us, you call the L1 contract, and it should then consume messages from the message box.
Why? Privacy! When pushing, we would be needing full calldata. Which for functions with private inputs is not really something we want as that calldata for L1 -> L2 transactions are committed to on L1, e.g., publicly sharing the inputs to a private function.
By instead pulling, we can have the "message" be something that is derived from the arguments instead. This way, a private function to perform second half of a deposit, could leak the "value" deposited and "who" made the deposit (as this is done on L1), but the new owner can be hidden on L2.
To support messages in both directions we logically require two of these message boxes (one in each direction), and then message passing between L1 and L2 is supported! However, due to the limitations of each domain, the message box for sending messages into the rollup and sending messages out are not fully symmetrical. In reality, the setup looks closer to the following:
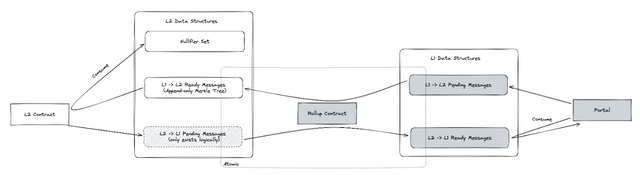
The L2 -> L1 pending messages set only exist logically, as it is practically unnecessary. For anything to happen to the L2 state (e.g., update the pending messages), the state will be updated on L1, meaning that we could just as well insert the messages directly into the ready set.
Rollup Contract
The rollup contract has a few very important responsibilities. The contract must keep track of the L2 rollup state root, perform state transitions and ensure that the data is available for anyone else to synchronise to the current state.
To ensure that state transitions are performed correctly, the contract will derive public inputs for the rollup circuit based on the input data, and then use a verifier contract to validate that inputs correctly transition the current state to the next. All data needed for the public inputs to the circuit must be from the rollup block, ensuring that the block is available. For a valid proof, the rollup state root is updated and it will emit an event to make it easy for anyone to find the data by event spotting.
As part of state transitions where cross-chain messages are included, the contract must "move" messages along the way, e.g., from "pending" to "ready".
Kernel Circuit
For L2 to L1 messages, the public inputs of a user-proof will contain a dynamic array of messages to be added, of size at most MAX_MESSAGESTACK_DEPTH, limited to ensure it is not impossible to include the transaction. The circuit must ensure, that all messages have a sender/recipient pair, and that those pairs exist in the contracts tree and that the sender is the L2 contract that actually emitted the message.
For consuming L1 to L2 messages the circuit must create proper nullifiers.
Rollup Circuit
The rollup circuit must ensure that, provided two states and and the rollup block , applying to using the transition function must give us , e.g., . If this is not the case, the constraints are not satisfied.
For the sake of cross-chain messages, this means inserting and nullifying L1 L2 in the trees, and publish L2 L1 messages on chain. These messages should only be inserted if the sender and recipient match an entry in the contracts leaf (as checked by the kernel).
Messages
While a message could theoretically be arbitrary long, we want to limit the cost of the insertion on L1 as much as possible. Therefore, we allow the users to send 32 bytes of "content" between L1 and L2. If 32 suffices, no packing required. If the 32 is too "small" for the message directly, the sender should simply pass along a sha256(content) instead of the content directly. The content can then either be emitted as an event on L2 or kept by the sender, who should then be the only entity that can "unpack" the message.
In this manner, there is some way to "unpack" the content on the receiving domain.
The message that is passed along, require the sender/recipient pair to be communicated as well (we need to know who should receive the message and be able to check). By having the pending messages be a contract on L1, we can ensure that the sender = msg.sender and let only content and recipient be provided by the caller. Summing up, we can use the structs seen below, and only store the commitment (sha256(LxLyCrossMsg)) on chain or in the trees, this way, we need only update a single storage slot per message.
struct L1Actor {
address: actorAddress,
uint256: chainid,
}
struct L2Actor {
bytes32: actorAddress,
uint256: version,
}
struct L1L2CrossMsg {
L1Actor: sender,
L2Actor: recipient,
bytes32: content,
bytes32: secretHash,
}
struct L2L1CrossMsg {
L2Actor: sender,
L1Actor: recipient,
bytes32: content,
}
The 32 bytes might practically need to be a field element.
uint256 p = 21888242871839275222246405745257275088548364400416034343698204186575808495617;
bytes32 content = bytes32(uint256(sha256(message)) % p);
The nullifier computation should include the index of the message in the message tree to ensure that it is possible to send duplicate messages (e.g., 2 x deposit of 500 dai to the same account).
To make it possible to hide when a specific message is consumed, the L1L2CrossMsg can be extended with a secretHash field, where the secretPreimage is used as part of the nullifier computation. This way, it is not possible for someone just seeing the L1L2CrossMsg on L1 to know when it is consumed on L2.
Combined Architecture
The following diagram shows the overall architecture, combining the earlier sections.
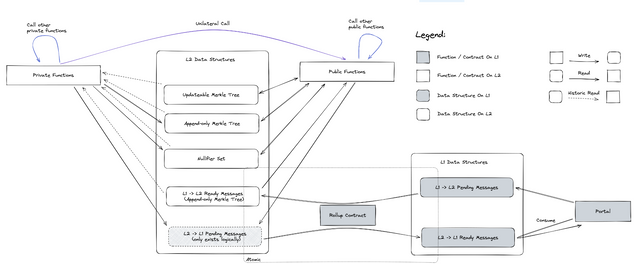
Linking L1 and L2 contracts
As mentioned earlier, there will be a link between L1 and L2 contracts (with the L1 part of the link being the portal contract), this link is created at "birth" when the contract leaf is inserted. However, the specific requirements of the link is not yet fully decided. And we will outline a few options below.
The reasoning behind having a link, comes from the difficulty of L2 access control (see "A note on L2 access control"). By having a link that only allows 1 contract (specified at deployment) to send messages to the L2 contract makes this issue "go away" from the application developers point of view as the message could only come from the specified contract. The complexity is moved to the protocol layer, that must now ensure that messages to the L2 contract are only sent from the specified L1 contract.
The design space for linking L1 and L2 contracts is still open, and we are looking into making access control more efficient to use in the models.
One L2 contract linking to one L1
One option is to have a 1:1 link between L1 and L2 contracts. This would mean that the L2 contract would only be able to receive messages from the specified L1 contract but also that the L1 should only be able to send messages to the specified L2 contract. This model is very restrictive, but makes access control easy to handle (but with no freedom).
It is possible to model many-to-many relationships through implementing "relays" and listing those. However, L2 contracts that want to use the relay would have to either use dynamic access control to ensure that messages are coming from the relayer and that they where indeed relayed from the correct L1 contract. Essentially back in a similar case to no links.
To enforce the restriction, the circuit must ensure that neither of the contracts have been used in any other links. Something that in itself gives us a few problems on frontrunning, but could be mitigated with a handshake between the L1 and L2 contract.
Many L2 contracts linking to one L1
From the L2 contract receiving messages, this model is very similar to the 1:1, only one L1 contract could be the sender of messages so no extra work needed there. On the L1 side of things, as many L2 could be sending messages to the L1 contract, we need to be able to verify that the message is coming from the correct L2 contract. However, this can be done using easy access control in the form of storage variables on the L1 contract, moving the design-space back to something that closely resembles multi-contract systems on L1.
When the L1 contract can itself handle where messages are coming from (it could before as well but useless as only 1 address could send), we don't need to worry about it being in only a single pair. The circuits can therefore simply insert the contract leafs without requiring it to ensure that neither have been used before.
With many L2's reading from the same L1, we can also more easily setup generic bridges (with many assets) living in a single L1 contract but minting multiple L2 assets, as the L1 contract can handle the access control and the L2's simply point to it as the portal. This reduces complexity of the L2 contracts as all access control is handled by the L1 contract.
Standards
Structure of messages
The application developer should consider creating messages that follow a structure like function calls, e.g., using a function signature and arguments. This will make it easier for the developer to ensure that they are not making messages that could be misinterpreted by the recipient. Example could be using amount, token_address, recipient_address as the message for a withdraw function and amount, token_address, on_behalf_of_address for a deposit function. Any deposit could then also be mapped to a withdraw or vice versa. This is not a requirement, but just good practice.
// Do this!
bytes memory message abi.encodeWithSignature(
"withdraw(uint256,address,address)",
_amount,
_token,
_to
);
// Don't to this!
bytes memory message = abi.encode(
_amount,
_token,
_to
);
Error Handling
Handling error when moving cross chain can quickly get tricky. Since the L1 and L2 calls are practically async and independent of each other, the L2 part of a withdraw might execute just fine, with the L1 part failing. If not handling this well, the funds might be lost forever! The contract builder should therefore consider in what ways his application can fail cross chain, and handle those cases explicitly.
First, entries in the outboxes SHOULD only be consumed if the execution is successful. For an L2 -> L1 call, the L1 execution can revert the transaction completely if anything fails. As the tx can be atomic, the failure also reverts the consumption of the entry.
If it is possible to enter a state where the second part of the execution fails forever, the application builder should consider including additional failure mechanisms (for token withdraws this could be depositing them again etc).
For L1 -> L2 calls, a badly priced L1 deposit, could lead to funds being locked in the bridge, but the message never leaving the L1 inbox because it is never profitable to include in a rollup. The inbox must support cancelling after some specific deadline is reached, but it is the job of the application builder to setup their contract such that the user can perform these cancellations.
Generally it is good practice to keep cross-chain calls simple to avoid too many edge cases and state reversions.
Error handling for cross chain messages is handled by the application contract and not the protocol. The protocol only delivers the messages, it does not ensure that they are executed successfully.
Designated caller
A designated caller is the ability to specify who should be able to call a function that consumes a message. This is useful for ordering of batched messages, as we will see in a second.
When doing multiple cross-chain calls as one action it is important to consider the order of the calls. Say for example, that you want to do a uniswap trade on L1 because you are a whale and slippage on L2 is too damn high.
You would practically, withdraw funds from the rollup, swap them on L1, and then deposit the swapped funds back into the rollup. This is a fairly simple process, but it requires that the calls are done in the correct order. For one, if the swap is called before the funds are withdrawn, the swap will fail. And if the deposit is called before the swap, the funds might get lost!
As the message boxes only will allow the recipient portal to consume the message, we can use this to our advantage to ensure that the calls are done in the correct order. Say that we include a designated "caller" in the messages, and that the portal contract checks that the caller matches the designated caller or designated is address(0) (anyone can call). When the message are to be consumed on L1, it can compute the message as seen below:
bytes memory message = abi.encodeWithSignature(
"withdraw(uint256,address,address)",
_amount,
_to,
_withCaller ? msg.sender : address(0)
);
This way, the message can be consumed by the portal contract, but only if the caller is the designated caller. By being a bit clever when specifying the designated caller, we can ensure that the calls are done in the correct order. For the uniswap example, say that we have a portal contracts implementing the designated caller:
contract TokenPortal {
function deposit(
uint256 _amount,
bytes32 _to,
bytes32 _caller,
) external returns (bytes32) {
bytes memory message = abi.encodeWithSignature(
"deposit(uint256,bytes32,bytes32)",
_amount,
_to,
_caller
);
ASSET.safeTransferFrom(msg.sender, address(this), _amount);
return INBOX.sendL2Message(message);
}
function withdraw(uint256 _amount, address _to, bool _withCaller) external {
// Including selector as message separator
bytes memory message = abi.encodeWithSignature(
"withdraw(uint256,address,address)",
_amount,
_to,
_withCaller ? msg.sender : address(0)
);
OUTBOX.consume(message);
ASSET.safeTransfer(_to, _amount);
}
}
contract UniswapPortal {
function swapAndDeposit(
address _inputTokenPortal,
uint256 _inAmount,
uint24 _fee,
address _outputTokenPortal,
bytes32 _aztecRecipient,
bool _withCaller
) public (bytes32) {
// Withdraw funds from the rollup, using designated caller
TokenPortal(_inputTokenPortal).withdraw(_inAmount, address(this), true);
// Consume the message to swap on uniswap
OUTBOX.consume(
abi.encodeWithSignature(
"swap(address,uint256,uint24,address,bytes32,address)",
_inputTokenPortal,
_inAmount,
_fee,
_outputTokenPortal,
_aztecRecipient,
_withCaller ? msg.sender : address(0)
)
);
// Perform swap on uniswap
uint256 amountOut = ...;
// Approve token to _outputTokenPortal
// Deposit token into rollup again
return TokenPortal(_outputTokenPortal).deposit(
amountOut, _aztecRecipient, bytes32(0)
);
}
}
We could then have withdraw transactions (on L2) where we are specifying the UniswapPortal as the caller. Because the order of the calls are specified in the contract, and that it reverts if any of them fail, we can be sure that it will execute the withdraw first, then the swap and then the deposit. Since only the UniswapPortal is able to execute the withdraw, we can be sure that the ordering is ensured. However, note that this means that if it for some reason is impossible to execute the batch (say prices moved greatly), the user will be stuck with the funds on L1 unless the UniswapPortal implements proper error handling!
Designated callers are enforced at the contract level for contracts that are not the rollup itself, and should not be trusted to implement the standard correctly. The user should always be aware that it is possible for the developer to implement something that looks like designated caller without providing the abilities to the user.
Open Questions
- Can we handle L2 access control without public function calls?
- Essentially, can we have "private shared state" that is updated very sparingly but where we accept the race-conditions as they are desired in specific instances.
- What is the best way to handle "linking", with efficient access control, could use this directly.
- What is the best way to handle messages in a multi-rollup system? E.g., rollup upgrade is rejected by some part of users that use the old rollup.
- What happens to pending messages (sent on old system then upgrade)?
- Should both versions push messages into same message boxes?
- How should users or developers signal what versions their contracts respects as the "current" version?
Participate
Keep up with the latest discussion and join the conversation in the Aztec forum.